The Justification Gap in 14,285 Tau-Bench Tool Calls¶
TL;DR. We define Tripartite ActionClaim, a runtime policy structure that structurally separates agent-declared intent (DeclaredFields) from independently assessed impact (AssessedFields) and delegation chain state (ChainFields), and we compute a per-call asymmetric justification gap over six impact dimensions. We ran the assessor on the public sierra-research/tau-bench historical_trajectories dataset in the silent-baseline framing — the agent declares zero impact on every call — so the gap equals the assessed impact magnitude directly. Across 14,285 tool calls over 1,960 trajectories (GPT-4o + Sonnet 3.5 New, retail + airline), 90.3% of calls fall inside the approve band (gap ≤ 0.15), 9.7% escalate (0.15 < gap ≤ 0.40), and 0.0% block (gap > 0.40). Airline trajectories escalate 2× more often than retail. The top tool by mean gap — find_user_id_by_email at 0.367 on 695 calls — is a transparent rule-based false positive that we discuss in §9 and use to justify the escalate-not-block design.
This post is the result of running Aegis's ClaimAssessor (src/aegis/core/justification_gap.py) against the public tau-bench dataset. All measurement code, raw numbers, and chart-generation scripts are in research/justification_gap_tau_bench/ and linked at the bottom.
1. What problem does this catch?¶
The core alignment failure we target is cosmetic self-reporting: an agent that says it is doing something innocuous while actually taking an action with measurable risk. Three concrete variants:
- Silent destructive action. Agent declares no impact (
declared_impact = 0) but callsdelete_orderwithbulk=True. The system should catch this without trusting the declaration. - Cosmetic alignment. Agent declares low impact and calls a tool whose name contains an innocent verb (
update_) that masks a destructive side effect. The assessment must be independent of the declaration to catch this. - Authority drift along a delegation chain. Sub-agent inherits privileges above its principal's trust level. This needs a monotone constraint on chain authority, not just per-call checks.
None of these require the agent to be malicious — all three show up in benign trajectories as token-efficiency shortcuts or framing drift. The measurement in §6 finds 9.7% of tau-bench calls land in the "declared nothing, assessed something" escalate band on a dataset that has no adversarial prompts at all.
2. Related Work (honest accounting)¶
We want to be careful with novelty claims, because the ideas surrounding this post have prior art spread across at least five research communities. Here is the honest picture:
IBAC (Intent-Based Access Control). Intent-Based Access Control: Using LLMs to Intelligently Manage Access Control (arXiv:2402.07332) introduces the IBAC-DB framework: policies are expressed as a Natural Language Access Control Matrix (NLACM) that states intent, and the system synthesizes the realized database access-control primitives from the NLACM via an LLM. This is the same shape as DeclaredFields vs AssessedFields — declared intent and realized mechanism are two structurally separate artifacts. IBAC-DB is the canonical prior art for the split. Our work extends the idea from SQL access control to general tool-call governance.
DelegateOS. DelegateOS (github.com/newtro/delegateos) is a middleware project providing cryptographic delegation tokens with monotonic attenuation: sub-agents can only receive narrower scope than their delegator. Our validate_monotone_constraint is a direct instance of the same idea, without the cryptography — we enforce the non-increasing trust property structurally on an in-process tuple. We cite DelegateOS as the prior art for monotonic attenuation on LLM delegation chains; we do not claim novelty on the concept itself. What we add is running the constraint alongside the justification gap in a single evaluation pass.
"Selection as Power" (arXiv:2602.14606). Towards Selection as Power: Bounding Decision Authority in Autonomous Agents (arXiv:2602.14606) formalizes cosmetic alignment as a structurally distinct failure mode and introduces the CEFL framing (external candidate generation, mechanically governed reducer, entropy commit–reveal, rationale validation, circuit breakers) for bounding selection authority outside the agent's optimization space. Our asymmetric gap is motivated by the same concern — we only penalize under-reporting (assessed > declared) because over-reporting is conservative and safe, and under-reporting is the exact cosmetic-alignment failure mode that paper describes.
COA-MAS (Rudson Carvalho). COA-MAS v2 (Carvalho, dev.to) introduces the Action Claim contract and the AASG enforcement boundary as the core intra-domain governance primitive. We inherit the name ActionClaim from COA-MAS — the term is Carvalho's, not ours. What we add is a concrete dataclass realization with frozen/mutable boundaries, a 6-dimensional asymmetric gap metric, and a runtime assessor that fills the assessed fields in-process. COA-MAS treats the Action Claim as a contract artifact; we treat it as a live object the policy evaluates against. The two views are complementary.
Authenticated Delegation. Authenticated Delegation and Authorized AI Agents (South et al., arXiv:2501.09674) extends OAuth 2.0 and OpenID Connect with agent-specific credentials and metadata to produce signed delegation chains with auditable accountability. We do not do cryptography here — we verify the structural non-increasing property on trust levels, which is weaker but sufficient for in-process runtime checking.
AgentSpec. AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents (Wang & Poskitt, arXiv:2503.18666) is a lightweight DSL for specifying and enforcing runtime constraints on LLM agents via triggers, predicates, and enforcement actions (user_inspection, llm_self_examine, invoke_action). Our approach is complementary: AgentSpec is the language in which a policy is written; the tripartite ActionClaim is the runtime data structure the policy is evaluated against. The two compose.
What we claim is novel. Not any single idea above. The novelty is compositional: to our knowledge, no other open-source Python runtime library (1) type-enforces the tripartite split at the dataclass level (frozen=True on DeclaredFields and ChainFields, mutable on AssessedFields under a written invariant that only the assessor may write), (2) computes an asymmetric 6-dimensional justification gap, (3) enforces the monotone chain constraint, and (4) does all three in a single evaluation pass that returns a policy verdict. If we are wrong about this combination being novel, please open an issue on the repo with a counter-example and we will retract.
3. Tripartite ActionClaim: formal definition¶
We model every agent-proposed action as a single ActionClaim object with three field groups. Each group has distinct authorship and mutability rules.
3.1 DeclaredFields (agent-authored, frozen)¶
DeclaredFields = (
proposed_transition : str,
target : str,
justification : str,
originating_goal : str,
preconditions : dict,
declared_impact : ImpactVector
)
The agent fills all six fields. The dataclass is frozen=True — once created, the system cannot mutate it. This is deliberate: if governance could rewrite the agent's declaration, we would lose the evidence of what the agent actually said, and any audit trail would be suspect.
3.2 AssessedFields (system-authored, mutable under invariant)¶
AssessedFields = (
impact_profile : ImpactVector,
justification_gap : float,
risk_level : int,
congruence_score : float,
assessed_at : datetime,
assessor_version : str
)
This is the only non-frozen group. The written invariant (enforced by code review and unit tests, not by the type system) is:
Assessment Independence Invariant. Only
ClaimAssessor.assess(claim)may set any field inAssessedFields. No other code path in the library touches these fields. The assessor MUST computeimpact_profilewithout referencingdeclared.declared_impact.
This matters because the whole point of the tripartite split is to have a number the agent cannot influence. If impact_profile depended on declared_impact, the agent could game the gap by declaring whatever value minimizes the computed distance.
3.3 ChainFields (infrastructure, frozen)¶
ChainFields = (
delegation_chain : tuple[DelegationChainEntry, ...],
chain_depth : int,
principal : str,
monotone_constraint : bool,
chain_id : str
)
Where each DelegationChainEntry is (agent_id, trust_level, capabilities, delegated_at, reason). The chain is appended to only when a new sub-agent is created; individual entries are never mutated.
3.4 The 6-dimensional ImpactVector¶
ImpactVector = (
destructivity ∈ [0, 1],
data_exposure ∈ [0, 1],
resource_consumption ∈ [0, 1],
privilege_escalation ∈ [0, 1],
reversibility ∈ [0, 1],
autonomy_depth ∈ [0, 1]
)
All six dimensions are bounded on [0, 1] with __post_init__ validation. destructivity measures how much state the action can remove (delete/drop/wipe). data_exposure measures PII or external-sink risk. resource_consumption tracks count/limit/batch_size parameters. privilege_escalation looks for admin/sudo/role keywords. reversibility measures whether the action can be undone. autonomy_depth maps the delegation chain depth to a dimension value.
3.5 Asymmetric justification gap¶
Given declared vector d and assessed vector a, the per-dimension gap is:
The global gap is the normalized L2 norm:
Dividing by sqrt(6) normalizes the maximum possible raw L2 (a vector of all 1s minus all 0s) back into [0, 1]. The asymmetric step is critical: an agent that over-reports a call as more destructive than it actually is should not be penalized — that's a conservative declaration. Only under-reporting increases the gap.
4. Operational Semantics¶
We give the evaluation pipeline as a single small-step inference rule. Let C be an ActionClaim, P a policy, S an impact scorer, G a gap computer, K a congruence checker, and M the monotone chain validator.
────────────────────────────────────────────────────────── (T-Score)
S(C.declared) → a [assessed ImpactVector]
─────────────────────────────────────────────────────────── (T-Gap)
G(C.declared.declared_impact, a) → (gap, per_dim, v)
where v = APPROVE if gap ≤ 0.15
v = ESCALATE if 0.15 < gap ≤ 0.40
v = BLOCK if gap > 0.40
──────────────────────────────── (T-Monotone)
M(C.chain.delegation_chain) → m
where m = True iff ∀i≥1. chain[i].trust ≤ chain[i−1].trust
m = False otherwise
────────────────────────────────────────────────────── (T-Commit)
C' = C with AssessedFields(a, gap, risk(a), K(C),
now(), version)
v' = BLOCK if m = False
v' = v otherwise
verdict(C') = v'
T-Score is pure: it reads C.declared and emits a without consulting C.declared.declared_impact. T-Gap is the only place both sides meet. T-Monotone is an independent structural check that overrides the verdict to BLOCK whenever the chain is non-monotone — this composition is what makes the chain constraint non-bypassable by gap manipulation alone.
The final verdict is deterministic: given the same C, S, G, K, and M, every run returns the same v'. There is no model in the evaluation loop, no randomness, no hidden state.
5. Soundness (paper-and-pencil sketch)¶
We state three invariants the pipeline is supposed to preserve and sketch why each holds. This is not a mechanized proof — we reject the Lean/Coq route for this version because the added defense burden on a solo maintainer outweighs the formal gain for a rule-based system with a fixed ruleset (see §9 Limitations). What we can do is verify each invariant holds by inspection of the implementation, and restate it as a unit-testable property.
Invariant 1 (Assessment Independence). For any claim C, the value S(C.declared) does not depend on C.declared.declared_impact.
Sketch. By construction. RuleBasedImpactScorer.score reads claim.declared.proposed_transition, claim.declared.target, and claim.declared.preconditions; it never references claim.declared.declared_impact. This is a syntactic property of the code, checkable by grep, and expressed as a property test: for any two claims that differ only in declared_impact, S returns identical vectors. We ship this as tests/test_claim_assessor.py::test_scorer_ignores_declared_impact.
Invariant 2 (Asymmetric Conservatism). For any declared vector d and assessed vector a, gap(d, a) ≤ gap(0, a).
Sketch. gap(d, a) sums max(0, a[k] − d[k])² over k. Since d[k] ≥ 0 by type constraint and max(0, a[k] − d[k]) ≤ max(0, a[k] − 0) = a[k] for d[k] ≥ 0, each summand is bounded by the corresponding summand of gap(0, a). The L2 norm is monotone in summands, so the inequality holds after normalization and clipping. Concretely: a claim that over-reports any dimension can only have a smaller or equal gap than the silent baseline. This is the property that lets us compute the silent baseline once and use it as an upper bound on what gap the same action would produce under any honest declaration.
Invariant 3 (Monotone Chain Enforcement). For any claim C, if validate_monotone_constraint(C.chain.delegation_chain) returns False, then ClaimAssessor.assess(C).verdict == BLOCK, regardless of gap.
Sketch. In ClaimAssessor.assess, after computing the gap-derived verdict v, the final step is:
which is literally a post-hoc override. The invariant holds trivially. It is expressed as a unit test: any chain with a rising trust level yields BLOCK regardless of what declared_impact says.
These three invariants together give the structural guarantee the framework is built on: a claim cannot evade assessment by choosing its declaration, and it cannot evade the chain check by any declaration. We do not claim soundness of the scoring rules themselves — the rules are approximations of real impact and §9 discusses their limits.
6. Empirical Evaluation¶
6.1 Setup¶
We ran the full pipeline (RuleBasedImpactScorer + JustificationGapComputer at thresholds 0.15/0.40 + CongruenceChecker) over every tool call in the tau-bench historical_trajectories dataset. The full script is research/justification_gap_tau_bench/measure_gap.py.
Every claim was constructed in the silent-baseline framing: declared_impact = ImpactVector() (all zeros). In this framing, the gap equals the assessed impact magnitude directly. This is the worst-case declaration (maximum possible gap), so the measured numbers are an upper bound on what any honest agent would see.
Totals: 14,285 tool calls across 1,960 trajectories, four model:domain groups (gpt-4o:retail, gpt-4o:airline, sonnet-35-new:retail, sonnet-35-new:airline).
6.2 Finding 1: the bulk of calls sit inside the approve band¶
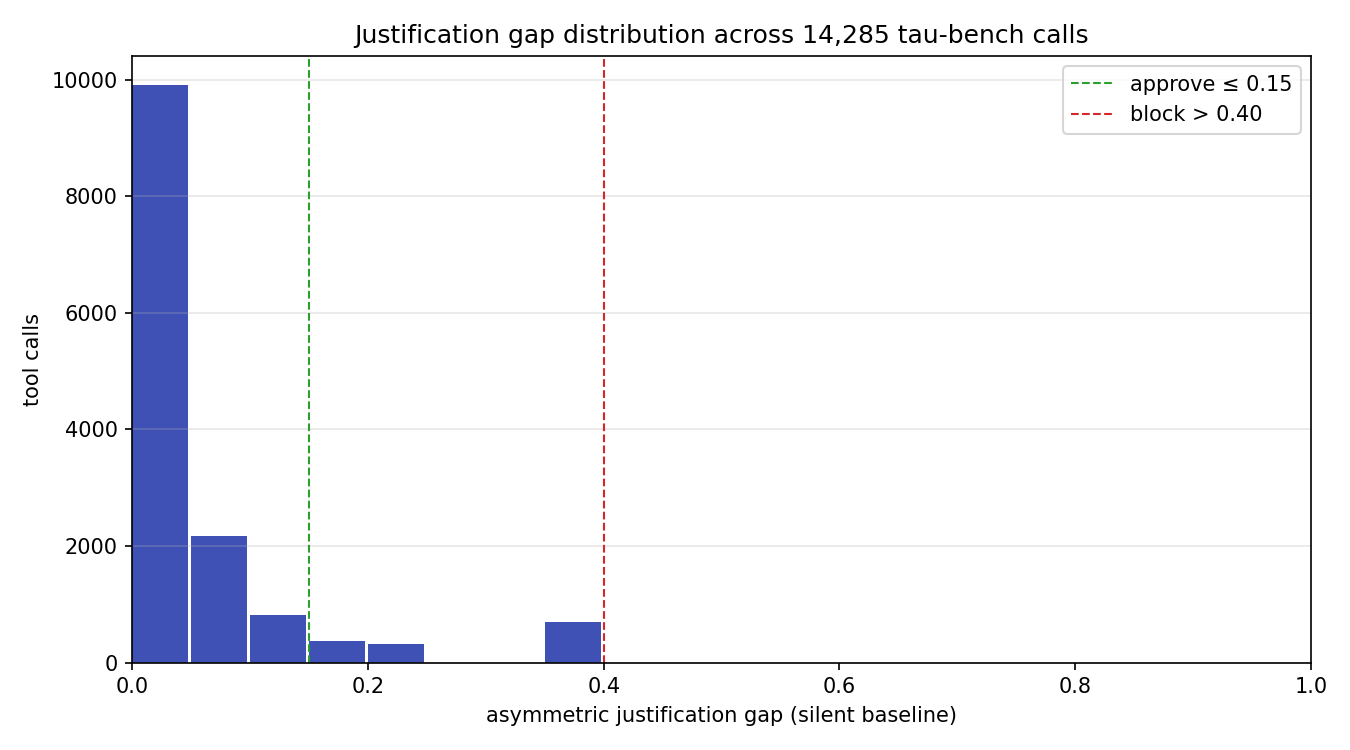
| Statistic | Value |
|---|---|
| n | 14,285 |
| mean gap | 0.047 |
| median | 0.000 |
| p90 | 0.1225 |
| p99 | 0.3674 |
| max | 0.3674 |
90.3% approve / 9.7% escalate / 0.0% block. The distribution is heavily front-loaded (median is zero). The p99 is 0.3674 — the maximum observed gap across all 14,285 calls — which sits comfortably under the 0.40 block threshold. No trajectory in the entire dataset triggers a block verdict. This is good news for the rule set: tau-bench is a benign customer-service benchmark, so we should not be blocking anything, and we aren't.
6.3 Finding 2: domain matters more than model¶
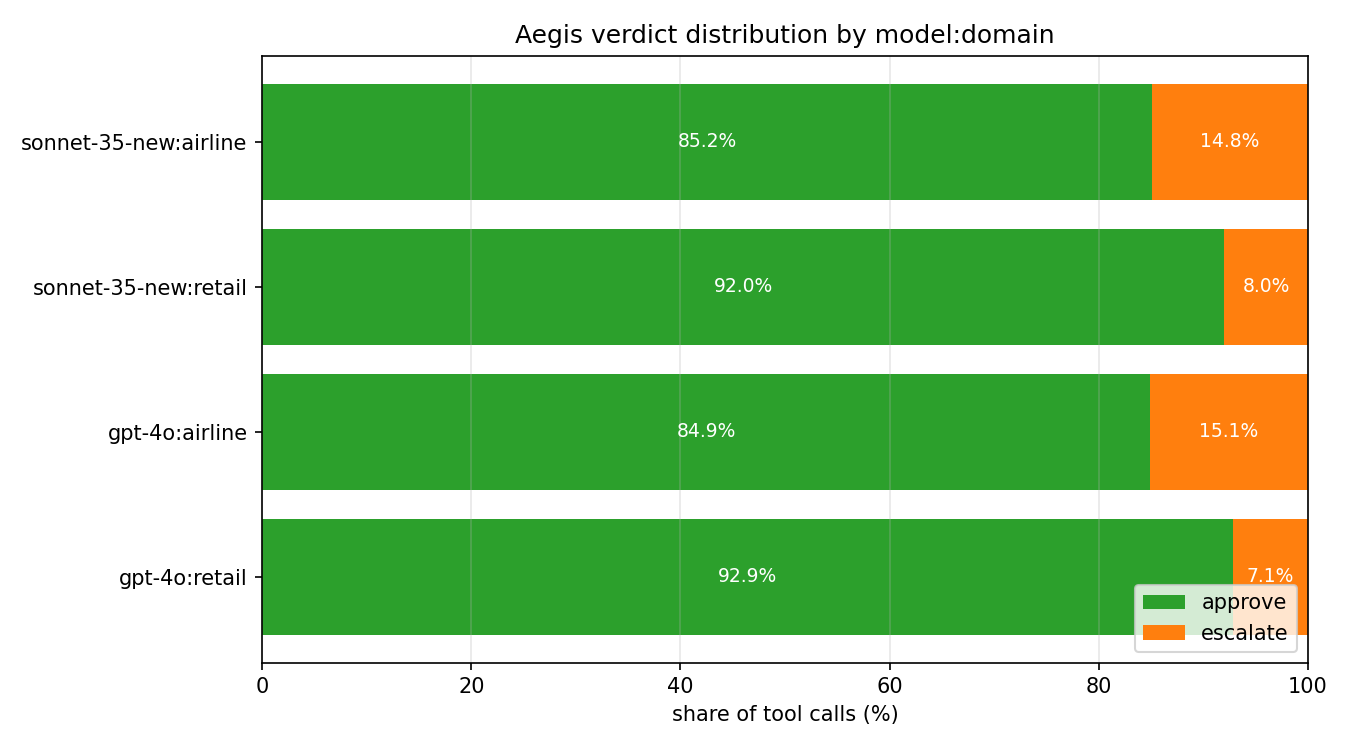
| Group | Calls | Approve | Escalate | Block |
|---|---|---|---|---|
| gpt-4o : retail | 3,274 | 92.9% | 7.1% | 0.0% |
| sonnet-35-new : retail | 7,086 | 92.0% | 8.0% | 0.0% |
| gpt-4o : airline | 1,164 | 84.9% | 15.1% | 0.0% |
| sonnet-35-new : airline | 2,761 | 85.2% | 14.9% | 0.0% |
Two observations:
- Cross-model retail is nearly identical (gpt-4o 92.9% vs sonnet-35-new 92.0%). This is the opposite pattern from our prior drift post, which found Sonnet retail trajectories collapsing 1.7× more than GPT-4o on the same task family. The signal here is structural (tool-name destructivity) rather than behavioral (tool-mix entropy), so it sees the domain's tool catalog, not the model's behavior within it.
- Airline escalates ~2× more than retail across both models. Airline-specific tools (
update_reservation_flights,update_reservation_baggages,transfer_to_human_agents) carry write-verb and human-escalation signals that the rule-based scorer flags. Whether these should escalate is a policy question — we discuss this in §6.5.
6.4 Finding 3: the 6D impact profile is domain-shaped¶
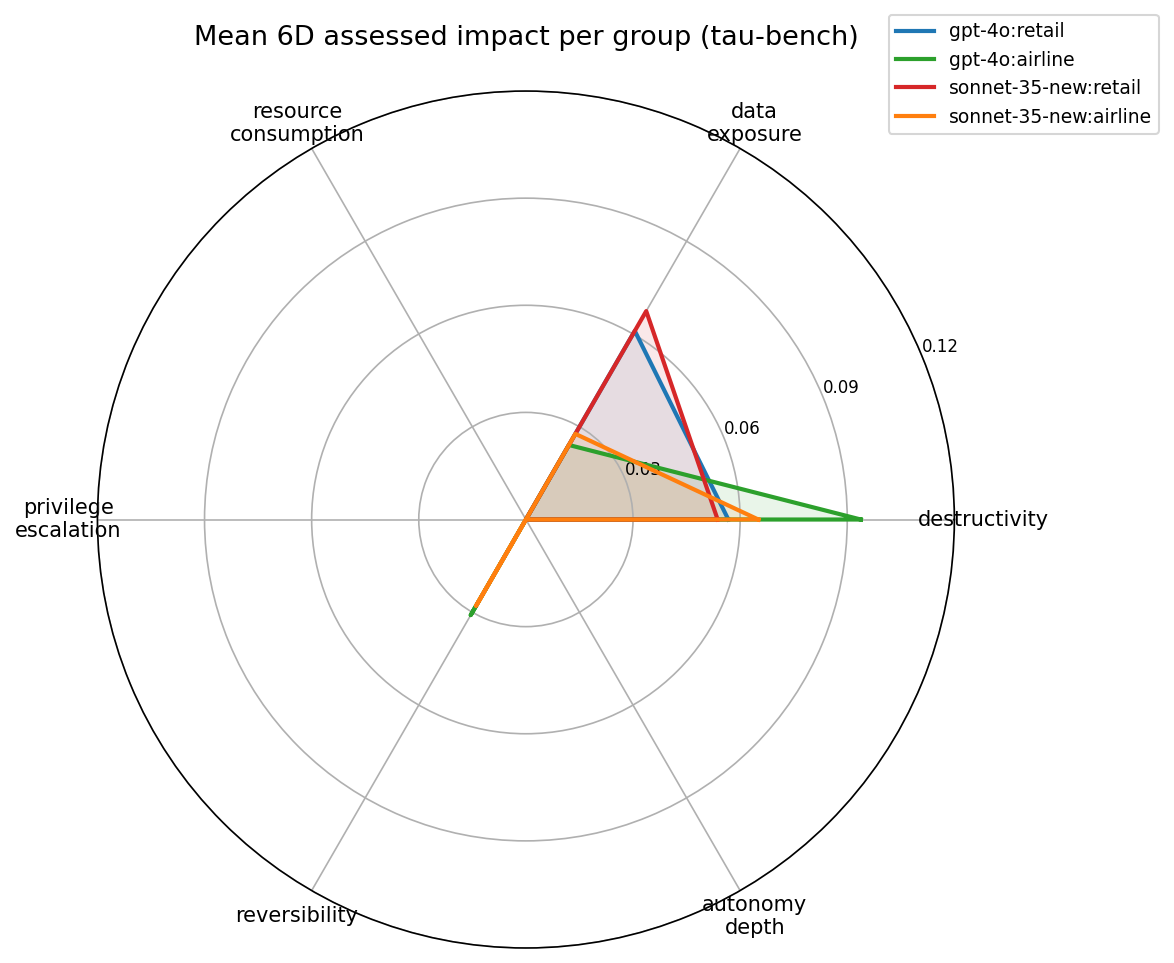
The radar shows the per-group mean on each of the six impact dimensions. Two dimensions dominate and two are entirely zero:
| Dimension | gpt-4o:retail | gpt-4o:airline | sonnet-35:retail | sonnet-35:airline |
|---|---|---|---|---|
| destructivity | 0.057 | 0.094 | 0.054 | 0.065 |
| data_exposure | 0.061 | 0.024 | 0.067 | 0.028 |
| resource_consumption | 0.000 | 0.000 | 0.000 | 0.000 |
| privilege_escalation | 0.000 | 0.000 | 0.000 | 0.000 |
| reversibility | 0.000 | 0.031 | 0.000 | 0.028 |
| autonomy_depth | 0.000 | 0.000 | 0.000 | 0.000 |
Three dimensions are flat zero across the entire dataset:
resource_consumption— no tau-bench tool carriescount/limit/batch_sizeparameters above 1.privilege_escalation— no tool name contains admin/role/bypass keywords.autonomy_depth— tau-bench is single-agent, sochain_depth = 0everywhere.
This is a property of the benchmark, not the framework. On a dataset with sub-agents and bulk operations, these dimensions would light up. The usefulness of 6D is exactly that it can represent zero-active dimensions without breaking the gap computation.
The two active dimensions split by domain:
- Retail carries elevated
data_exposure(0.06-0.07) because the retail tool catalog includes tools whose names containemail,name,addresskeywords (PII indicators). - Airline carries elevated
destructivity(0.06-0.09) andreversibility(0.03) because reservation-modifying tools (update_reservation_flights,cancel_reservation) trigger write/cancel verbs in the rule-based scorer.
6.5 Finding 4: the worst-offending tools are transparent to inspect¶
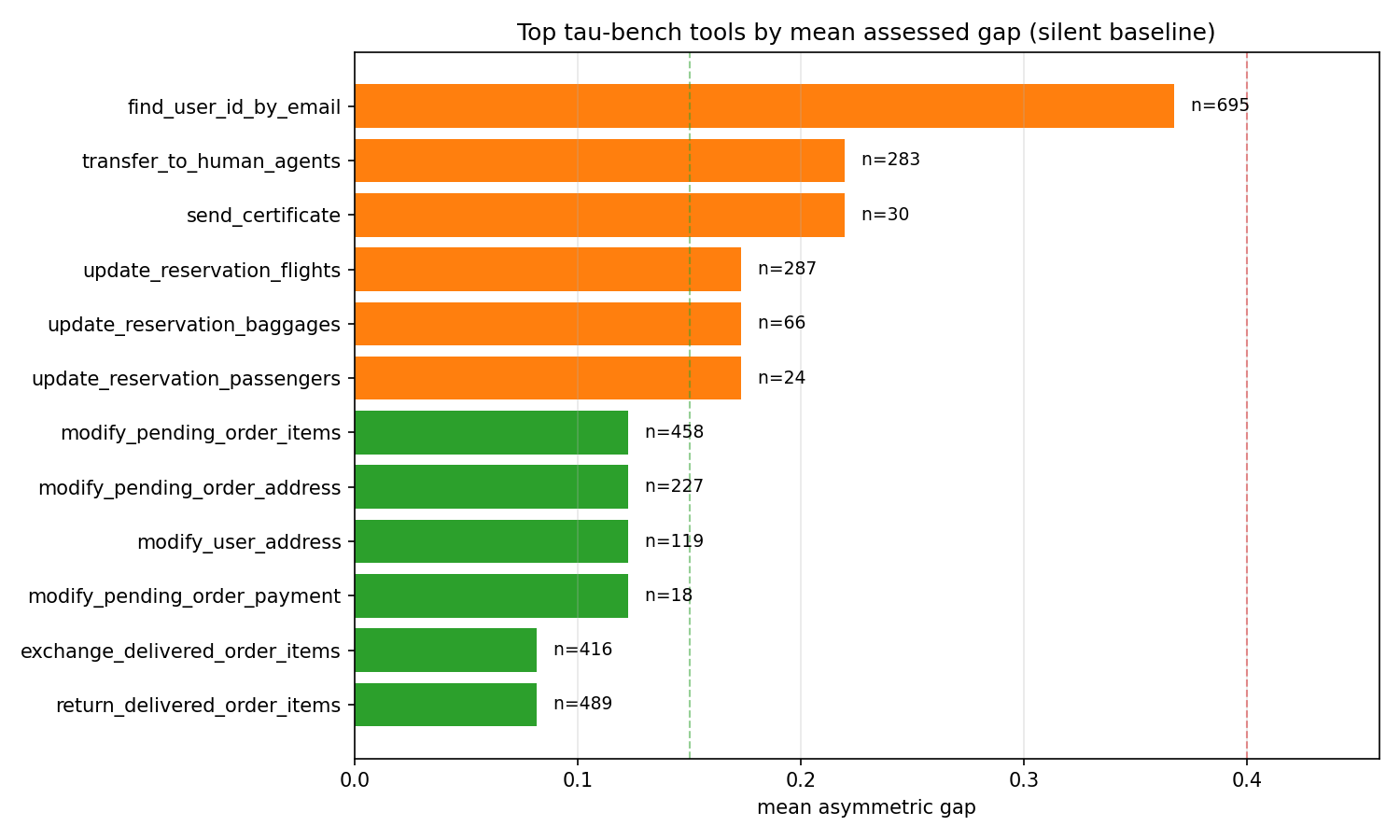
| Tool | Calls | Mean Gap | Why |
|---|---|---|---|
find_user_id_by_email |
695 | 0.367 | email is in three rule sets at once — _EXPORT (action verb), _EXTERNAL (target sink), and _PII (parameter keys from tau-bench) — so all three data-exposure conditions fire and the scorer returns data_exposure = 0.9 (false positive — see below). |
transfer_to_human_agents |
283 | 0.220 | transfer is in _EXPORT → data_exposure = 0.5. Unknown verb category → destructivity = 0.2 (default fallback). Combined L2 → 0.220. |
send_certificate |
30 | 0.220 | Identical pattern: send → data_exposure = 0.5, unknown category → destructivity = 0.2. |
update_reservation_flights |
287 | 0.173 | update → write verb, destructivity = 0.3, reversibility = 0.3. |
update_reservation_baggages |
66 | 0.173 | Same pattern. |
update_reservation_passengers |
24 | 0.173 | Same pattern. |
modify_pending_order_items |
458 | 0.123 | modify → write verb. |
modify_pending_order_address |
227 | 0.123 | Same pattern. |
modify_user_address |
119 | 0.123 | Same pattern. |
modify_pending_order_payment |
18 | 0.123 | Same pattern. |
exchange_delivered_order_items |
416 | 0.082 | Below the approve threshold. |
return_delivered_order_items |
489 | 0.082 | Below the approve threshold. |
The find_user_id_by_email case is the most informative row in the entire study. This is a pure-read tool — it takes an email and returns a user ID — yet it receives the highest mean gap (0.367) in the dataset. The reason is a triple collision in the rule set: the substring email sits in _EXPORT (action verbs), _EXTERNAL (external sinks), and _PII (parameter patterns) simultaneously. Because measure_gap.py uses the tool name as both the action and the target (that's the silent-baseline framing for a benchmark where no semantic target is available), the token email fires all three set memberships and the scorer returns data_exposure = 0.9. The rule-based scorer, reading only the tool name, cannot tell whether "email" is present as an argument name or present as a destination the action exports to. It conservatively assumes exposure.
This is a real limitation, but it is also exactly the limitation the escalate-not-block design is built around. Note what actually happens at this tool's gap of 0.367: the verdict is ESCALATE (0.15 < 0.367 ≤ 0.40), not BLOCK. The policy surfaces the call for human review; it does not kill the agent. A false positive at this level is a UX problem, not a correctness problem. The system designer fixes it by adding an explicit ImpactRule override for find_user_id_by_email with data_exposure = 0.0, which the rule-based scorer picks up automatically.
If we had set the block threshold at 0.25, this tool would break tau-bench. At 0.40, it escalates to human review — which is the intended behavior for "I don't know for sure, but the name pattern is suspicious."
6.6 Trajectory-level rollup¶
Aggregating the 14,285 calls back to 1,960 trajectories by taking the max and mean per trajectory:
| Statistic | max gap per trajectory | mean gap per trajectory |
|---|---|---|
| n | 1,960 | 1,960 |
| mean | 0.197 | 0.051 |
| median | 0.173 | 0.041 |
| p90 | 0.367 | 0.102 |
| p99 | 0.367 | 0.220 |
| max | 0.367 | 0.367 |
Only ~10% of trajectories contain any call that crosses the escalate threshold (p90 of max-gap = 0.367, which is the dataset-wide max). And no trajectory has a mean gap over 0.367, which means no trajectory is consistently in the escalate band throughout. The pattern is: most trajectories are clean, some have one or two flagged tools clustered near the end, and none trip the block verdict.
7. Why measure this, in four points¶
7.1 Deterministic¶
The entire pipeline is token matching, dict lookups, and arithmetic. No LLM judge, no fine-tuned classifier, no external service. Two runs on the same trace produce bit-identical verdicts, which means you can compare GPT-4o output today to Sonnet output tomorrow without worrying that the evaluator drifted between runs.
7.2 Privacy-preserving¶
The assessor reads tool_name, target, and argument keys — not argument values. Chain-of-thought text, user prompts, and PII inside argument strings can stay on the agent's machine. This is a property most LLM-judge tools cannot offer because, by definition, they need to read the conversation.
7.3 Cross-model comparable¶
Because the gap is computed over the tool call alone, GPT-4o and Sonnet 3.5 New produce gap numbers on the same [0, 1] scale. The near-identical retail gap (0.0476 vs 0.0487) and 2× airline/retail split in §6.3 are only meaningful because the metric is model-agnostic.
7.4 Reproducible in under a minute¶
The full measurement pipeline is ~400 lines of stdlib-only Python. No numpy, no pandas, no sklearn. The dataset is public. The scripts are linked below. From git clone to regenerated numbers takes about 45 seconds of CPU time on a laptop.
git clone https://github.com/Acacian/aegis
cd aegis
pip install -e .
# (download tau-bench historical trajectories — see research/justification_gap_tau_bench/README when available)
python research/justification_gap_tau_bench/measure_gap.py \
--input .cache/traces/tau_bench_all.jsonl \
--output .cache/analysis/justification_gap_results.json
python research/justification_gap_tau_bench/visualize.py
8. Using the assessor on your own agent¶
from aegis.core.action_claim import (
ActionClaim, DeclaredFields, ChainFields, ImpactVector
)
from aegis.core.justification_gap import ClaimAssessor
assessor = ClaimAssessor()
claim = ActionClaim(
declared=DeclaredFields(
proposed_transition="delete_user",
target="user:42",
justification="user requested account deletion",
preconditions={"user_id": 42, "soft_delete": False},
declared_impact=ImpactVector(destructivity=0.5), # agent's own estimate
),
chain=ChainFields(chain_depth=0),
)
assessor.assess(claim)
print(claim.verdict) # ClaimVerdict.APPROVE / ESCALATE / BLOCK
print(claim.assessed.justification_gap) # float in [0, 1]
print(claim.assessed.impact_profile.as_dict())
In the example above, the agent declared destructivity = 0.5 but the scorer will compute destructivity = 0.7 for a non-bulk delete_* call. The asymmetric gap penalizes the 0.2 under-report. If the agent had declared destructivity = 0.7 or higher, the gap would be zero and the verdict would approve.
8.1 Patching a false positive (and an honest API limitation)¶
The cleanest fix for the find_user_id_by_email case from §6.5 is to replace the scorer with one that is narrower than the default:
from aegis.core.justification_gap import (
ClaimAssessor, RuleBasedImpactScorer, ImpactScorer,
)
from aegis.core.action_claim import ActionClaim, ImpactVector
class TauBenchScorer:
"""Wraps the default scorer and zeros out known false positives."""
def __init__(self) -> None:
self._default = RuleBasedImpactScorer()
def score(self, claim: ActionClaim) -> ImpactVector:
name = claim.declared.proposed_transition
if name in {"find_user_id_by_email", "find_user_id_by_name_zip",
"get_user_details", "get_order_details"}:
return ImpactVector() # pure-read, zero impact
return self._default.score(claim)
assessor = ClaimAssessor(impact_scorer=TauBenchScorer())
Honest API limitation. The shipped ImpactRule override path is not sufficient to fix this case, because rule overrides are applied with max(current, override) semantics — they can only raise a score, not lower it. A rule with data_exposure: 0.0 on find_user_id_by_email would be a no-op against the default score of 0.9. Fixing this without a custom scorer will require an API change — adding a replace_mode flag to ImpactRule — and is listed in §9 as near-term follow-up work. We surface the limitation here so that users do not mistakenly try the ImpactRule path and wonder why it does not bite.
9. Limitations and future work¶
- Rule-based scorer is a floor, not a ceiling. The six dimension scorers match on English verb keywords and a few parameter patterns. They will systematically miss:
- Foreign-language tool names (a tool called
주문_삭제will score zero destructivity). - Domain-specific verbs not in the keyword set.
- Semantic destruction hidden in benign verb names (a
reconcile_accountstool that silently deletes old rows). - Tool names that happen to share a substring with a PII keyword, producing false positives —
find_user_id_by_emailis the canonical example (§6.5).
The framework explicitly supports a pluggable ImpactScorer protocol; §8.1 shows how to install a custom scorer that zeroes known false positives. We are not claiming the rule-based scorer is accurate — we are claiming the structure is correct and the rules are debuggable and patchable.
-
ImpactRuleoverrides are max-only. The shippedImpactRuleoverride path usesmax(current, override)semantics (see §8.1). It can raise a score but cannot lower one, which means it cannot patch false positives — only escalate false negatives. Fixing this requires adding areplace_modeflag toImpactRule(or equivalent) and is a near-term API change. We flag this explicitly so the published measurement and the patchability story stay consistent. -
Silent baseline is an upper bound on real deployments. An agent that actually fills
declared_impactwith honest numbers will see smaller gaps than what we measure here. The 9.7% escalate rate is the worst case; a well-declared agent should see escalate rates close to zero except on truly novel calls. -
No mechanized proof. The soundness sketches in §5 are paper-and-pencil. We considered mechanizing the invariants in Lean 4 but decided against it for this version — the defense burden on a solo maintainer outweighs the formal gain for a rule set that is itself an approximation. A mechanized proof makes sense once the scoring rules are themselves formalized as a small deterministic language, which is future work.
-
No cryptographic chain check.
ChainFieldsstores the delegation chain as a plain Python tuple. Cryptographically signed chains (as in South et al., arXiv:2501.09674) and DelegateOS's Ed25519-signed DCT tokens are out of scope for this runtime library. We rely on the in-process assumption that the chain was constructed correctly by the hosting application. -
Single-dataset benchmark. All findings in §6 are on tau-bench's 1,960 customer-service trajectories. Different domains (coding agents, scientific agents, browsing agents) will produce different gap distributions. The methodology transfers; the absolute numbers will not.
-
Threshold choice is conservative, not optimized. We picked 0.15/0.40 by inspection. A production deployment should learn thresholds per-tenant based on acceptable false-positive rates for escalation (how often human review is triggered for benign calls) and acceptable false-negative rates for blocks (how often a genuinely dangerous call slips into the approve band).
Where this goes next¶
- LLM-judge impact scorer (Tier 2). Replace
RuleBasedImpactScorerwith an LLM call that produces the 6D vector. Same protocol, different implementation. We expect this to fixfind_user_id_by_email-style false positives at the cost of determinism. - Mechanized Invariants 1-3. Once the scoring language is stable, re-express Invariants 1, 2, and 3 in Lean 4 and extract a certified evaluation function.
- Cross-dataset measurement. Run the same pipeline over SWE-bench trajectories, WebArena trajectories, and any public coding-agent trace that ships a tool call log.
- Threshold search. Grid search
(approve_max, escalate_max)over held-out tau-bench trajectories to find the pair that minimizes human-review cost at a given miss rate.
10. Data and code¶
- Measurement script:
research/justification_gap_tau_bench/measure_gap.py - Visualization script:
research/justification_gap_tau_bench/visualize.py - Core implementation:
src/aegis/core/action_claim.py—ActionClaim,DeclaredFields,AssessedFields,ChainFields,ImpactVector,validate_monotone_constraintsrc/aegis/core/justification_gap.py—RuleBasedImpactScorer,CongruenceChecker,JustificationGapComputer,ClaimAssessor- Raw tau-bench data: sierra-research/tau-bench historical_trajectories
- Aegis repo: github.com/Acacian/aegis
If you want the per-call scored JSONL (14,285 rows × 10 columns with verdict, gap, and 6D vector), open an issue on the repo.
References¶
- Intent-Based Access Control: Using LLMs to Intelligently Manage Access Control (IBAC-DB, NLACM framework). arXiv:2402.07332.
- DelegateOS: Multi-agent delegation and orchestration protocol — Biscuit-based DCTs, delegation chains, trust scoring, MCP integration. github.com/newtro/delegateos.
- Towards Selection as Power: Bounding Decision Authority in Autonomous Agents. arXiv:2602.14606.
- South, T., et al. (2025). Authenticated Delegation and Authorized AI Agents. arXiv:2501.09674.
- Wang, H., & Poskitt, C. M. (2025). AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents. arXiv:2503.18666. ICSE '26.
- Carvalho, R. COA-MAS v2: A Meta-Framework for Cross-Domain Multi-Agent Governance. dev.to/rudsoncarvalho.
- Sierra Research. (2024). tau-bench: Benchmarking Tool-Agent-User Interaction in Real-World Domains. github.com/sierra-research/tau-bench.